

IT ist am besten, wenn sie im Hintergrund funktioniert. In der Realität fällt sie aber oft genau dann auf, wenn etwas nicht mehr läuft: Die Website ist nicht erreichbar, E-Mail kommt nicht an, Systeme werden langsam oder ein Sicherheitsproblem taucht plötzlich auf. Viele Teams arbeiten dann reaktiv. Jemand meldet eine Störung, anschließend beginnt die Suche nach Ursache und Lösung. Das kostet Zeit, stört Abläufe und ist schwer planbar.
Proaktive IT setzt früher an. Statt nur auf Ausfälle zu reagieren, werden Signale und Risiken sichtbar gemacht, bevor sie den Arbeitsalltag treffen. Genau das ist der Punkt: Stabilität entsteht nicht durch Hoffnung, sondern durch Überblick. Wenn klar ist, was gerade passiert, was sich verschlechtert und wo Risiken oder Abhängigkeiten entstehen, lassen sich Probleme häufig beheben, bevor sie eskalieren.
Wir sind ein Open-Source-Systemhaus und betreiben IT so, dass sie verständlich bleibt und im Alltag messbar funktioniert. Dabei geht es nicht um eine Tool-Sammlung, sondern um ein System, das drei Dinge zuverlässig liefert: Erreichbarkeit, Stabilität im Tagesgeschäft und die Sicherheit, dass Backups und Systemupdates aktuell sind und zuverlässig durchgeführt werden.
Unser Ansatz: verständlich, messbar, im Alltag wirksam
1) Infrastruktur-Monitoring mit Zabbix
Der erste Schritt ist die Überwachung der technischen Basis. Dafür nutzen wir Zabbix, um die Systeme und Geräte im Blick zu behalten, die täglich gebraucht werden. Zabbix überwacht bei unseren Kunden unter anderem Windows-Server, Linux-Server und Firewalls sowie Netzwerkgeräte wie Switches, Access Points und NAS-Systeme.
Wichtig ist dabei nicht nur, ob etwas „an“ ist, sondern ob sich ein Problem anbahnt: Ressourcen werden knapp, Dienste verhalten sich ungewöhnlich oder ein Gerät wird instabil. So entsteht Frühwarnung statt Überraschung. Im Problemfall lässt sich die Ursache durch die Vielzahl gemessener Werte schneller eingrenzen. Das kann im ungünstigsten Fall eine Downtime einzelner Geräte nicht immer verhindern, hilft aber dabei, Probleme deutlich schneller zu analysieren und zielgerichtete Lösungen bereitzustellen.
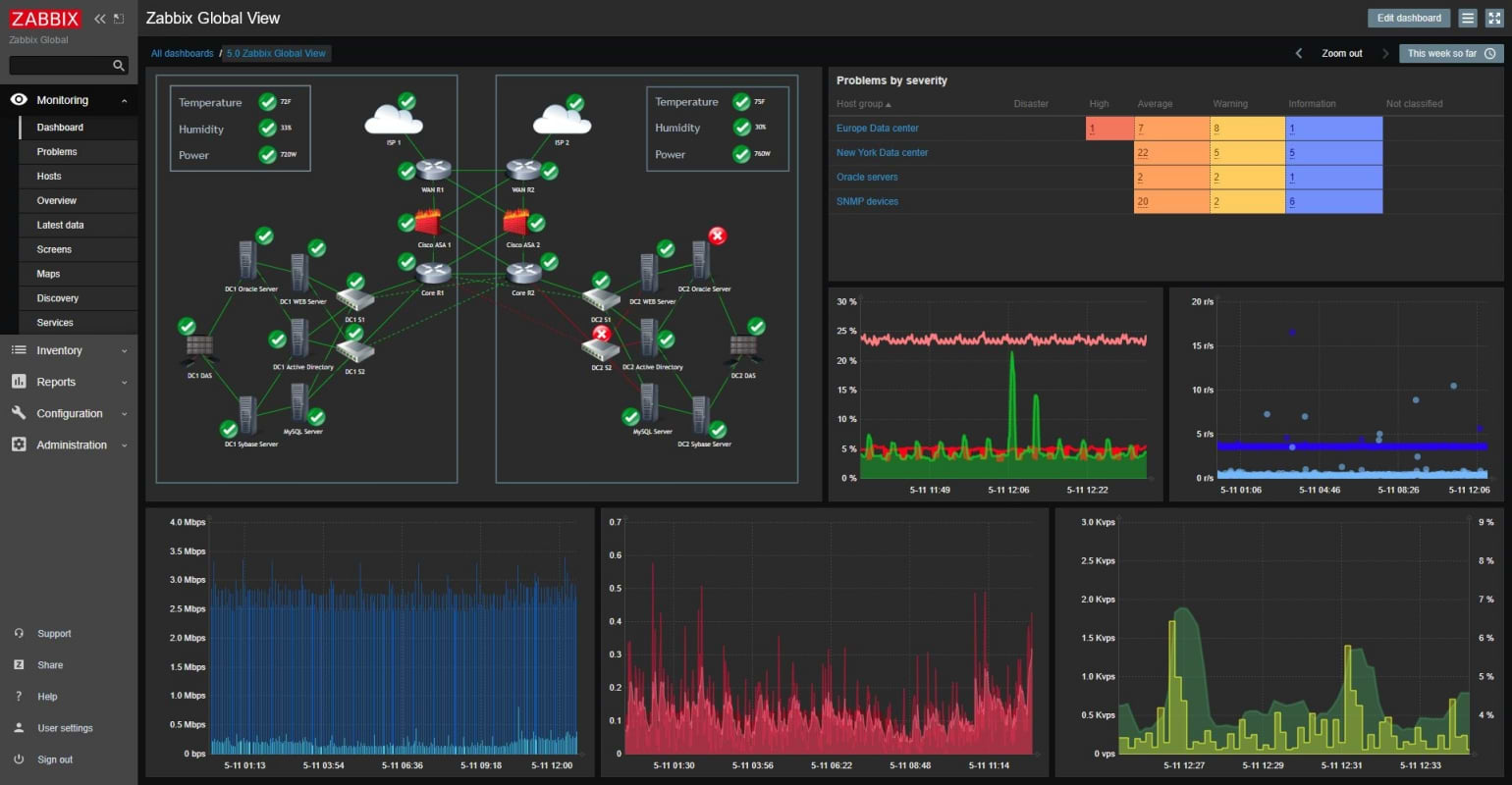
2) Erreichbarkeit Monitoring mit Uptime Kuma
Viele Probleme zeigen sich zuerst dort, wo Kunden oder Mitarbeitende direkt betroffen sind. Deshalb überwachen wir nicht nur intern, sondern auch aus externer Sicht, so wie es echte Nutzer erleben. Dafür setzen wir Uptime Kuma ein.
Kuma trackt bei unseren Kunden die öffentliche Uptime der Außenpräsenz wie Websites und Dienste, zum Beispiel über DNS-Anfragen und direkte Prüfungen. Zusätzlich überwachen wir die interne Erreichbarkeit wichtiger Dienste und Anwendungen sowie die E-Mail-Kommunikation. Das hilft besonders bei Themen, die sofort Wirkung nach außen und innen haben: Außenwirkung bleibt stabil, interne Abläufe brechen nicht plötzlich weg oder Probleme werden sehr früh erkannt und werden automatisiert an uns gemeldet.
3) Backup- und Automatisierung-Monitoring mit Pulse
Backups sind nur dann ein Sicherheitsnetz, wenn sie zuverlässig laufen und Probleme sofort auffallen. Hier nutzen wir Healthchecks.io, um sicher zu wissen, dass Backups wirklich durchgelaufen sind und damit wir uns jederzeit über die Aktualität vergewissern können.
Zusätzlich überwachen wir damit auch unsere Ansible Playbooks, die die Automatisierung, Updates und Verwaltung der Linux-Server übernehmen, die wir für Kunden betreiben. Dadurch wird Betrieb wiederholbar: Standards greifen, Updates laufen kontrolliert und Abweichungen werden sichtbar, statt unbemerkt liegenzubleiben.
4) Zusätzliche Überwachung der Windows-Welt
Für unsere verwalteten Windows-Systeme nutzen wir ACMP für eine zentralisierte Verwaltung. Bei Interesse kann auch der bereits veröffentlichte Blogbeitrag zum Thema „Zentralisierte Windows-Verwaltung“ gelesen werden.
Durch die zentrale Defender-Verwaltung sowie den Sicherheitsrisikenmanager können wir den Status der Geräte kontinuierlich einsehen und Korrekturen schnell vornehmen. Zudem bietet der Sicherheitsbereich die Möglichkeit, bekannte Sicherheitslücken auf den Geräten zu erkennen oder akute Sicherheitsbedrohungen per Alerting an uns zu melden. So können wir schnell Maßnahmen ergreifen, um die Gerätesicherheit zu gewährleisten.
5) Interne Alerterkennung in Ticket-Form
Damit wir die Ereignisse in den verwalteten Systemen jederzeit im Blick behalten und auch mitbekommen, wenn bei Kunden, Software oder Hardware Fragen oder Probleme auftreten, nutzen wir das Support-Ticket-Tool Zammad. Hier laufen Meldungen aus den eingesetzten Tools zusammen. Diese werden übersichtlich aufbereitet und in verschiedenen Ansichten strukturiert, damit jederzeit nachvollziehbar ist, was in der Infrastruktur gerade passiert.

Was das in der Praxis verändert
Unterm Strich geht es um vier Ergebnisse, die man im Arbeitsalltag spürt:
- weniger spürbare Ausfälle, weil Probleme früh sichtbar werden und oft vorher gelöst werden können,
- schnellere Lösungen, weil Ursachen klarer und nachvollziehbarer sind und weniger Suchzeit entsteht,
- mehr Sicherheit, weil Backups, Wartung und Updates nicht „irgendwann“ passieren, sondern täglich und sichtbar sind,
- mehr Ruhe im Team, weil IT seltener ungeplant Zeit frisst und weniger eskaliert.
Wenn dein Interesse geweckt wurde und du gemeinsam mit uns einen Überblick über deine Infrastruktur gewinnen möchtest, kannst du gerne ein kostenfreies Erstgespräch anfragen. Wir gehen dabei Schritt für Schritt durch deine IT-Infrastruktur, identifizieren potenzielle Schwachstellen und entwickeln konkrete Vorschläge, wie sich diese reduzieren lassen. Im Mittelpunkt stehen dabei sinnvolle, pragmatische Maßnahmen, die Stabilität und Sicherheit spürbar erhöhen und sich gut in den laufenden Betrieb einfügen.