
Am 08.02.2026 gegen 21:30 Uhr meldete unser Monitoring eine Großstörung, was für einen Sonntagabend eine recht ungewöhnliche Sache ist. Fast alle Dienste am Standort Nürnberg meldeten Erreichbarkeitsprobleme. Bei einer Störung dieser Größenordnung ist es unwahrscheinlich, dass tatsächlich alle Anwendungen gleichzeitig interne Störungen haben – deutlich wahrscheinlicher ist eine Störung der geteilten Infrastruktur: Firewall, Proxy oder der Infrastruktur des Standortproviders.

Abbildung: schematische Darstellung der Cloud-Architektur eines Standortes nach Zero-Trust-Prinzip
Was ist überhaupt los?
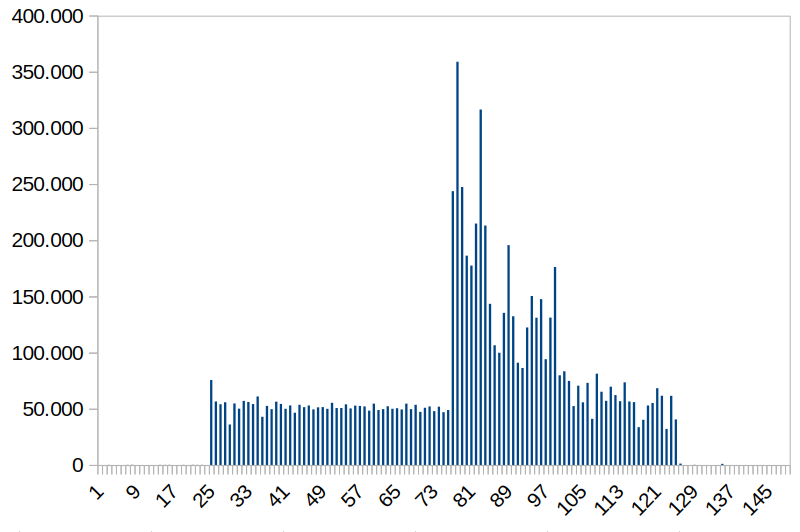
Die Rufbereitschaft gab sich also auf die Suche nach Ursachen und wurde recht bald fündig: Gegen 21:24 Uhr stieg die Last am zentralen Proxy des Standorts massiv an – auf mindestens das doppelte einer üblichen Spitzenbelastung im Regelbetrieb (für Sonntagnacht umso ungewöhnlicher). Auch das kann wiederum unterschiedliche Gründe haben: Häufig eine Fehlkonfiguration, die durch eine nicht-optimierte Einstellung Last generiert, im worst case ein Angreifer, der es geschafft hat, auf dem Host einen Crypto-Miner zu installieren, der nun lustig Bitcoins mined (soll es alles schon gegeben haben 😉 ) – oder eben ein Angriff von außen.

Abbildung: Last des zentralen Proxy-Servers am Standort. Links als Wellen sind die üblichen Tagesrhythmen der Woche zu sehen, rechts eine außergewöhnlich hohe Last
Ein Blick in die Logs offenbarte, dass eines unserer Kundensysteme, pdc-europe.tv, ab 21:24 Uhr plötzlich mit einer durchschnittlichen Zugriffszahl von 50.000 – 60.000 Zugriffen pro Minute konfrontiert wurde:
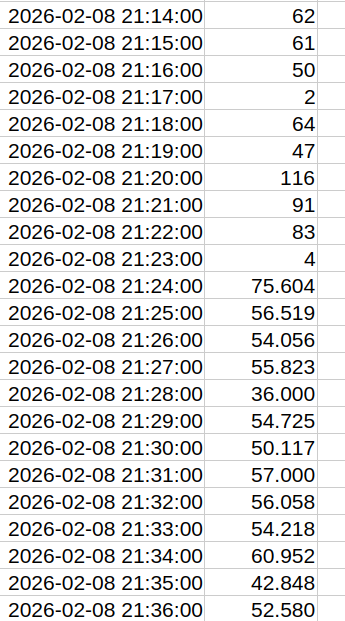
Abbildung: Zugriffszahlen auf pdc-europe.tv pro Minute. Oben die zu erwartende Menge an Zugriffen Sonntagnachts
Höhere Zugriffszahlen sind grundsätzlich nichts Ungewöhnliches – in der Halbzeitpause der Europameisterschaften können auch größere Mengen zustande kommen, allerdings nicht soooo viel und vor allem nicht sonntags um 21:30 Uhr!
Was ist ein DDoS-Angriff und was macht man dagegen?
Die Zeit warf uns auch Rätsel auf – ein DDoS-Angriff Sonntagnachts? DDoS bedeutet “Distributed Denial of Service” und ist die stumpfeste Form eines Angriffs: Zentral durch einen sog. “Command-and-Control-Server” gesteuert rufen viele Tausend bis Millionen verteilte Clients (PCs, Laptops, Server, …) die gleiche Website oder Anwendung auf mit dem Ziel, sie für andere nicht mehr erreichbar zu machen. In Zeiten, in denen jedes Gerät “smart” wird und jede Solarzelle “im Internet hängt”, nehmen DDoS-Angriffe massiv zu, da jedes gekaperte smarte Gerät potenziell als Client für einen Angrif missbraucht werden kann (idR. ohne, dass die besitzende Person etwas davon mitbekommt). So berichtet Cloudflare, dass 2025 die Anzahl der DDoS-Angriffe weltweit 2025 nochmal um 121 Prozent ggü. dem Vorjahr auf ~5.376 Angriffe pro Stunde(!) gestiegen sind. Da idR. nichts wirklich dabei kaputt gehen kann, sind die Schadensvektoren entweder Reputationsverlust, Verlust von Umsätzen (da ein Webshop in der Zeit z. B. nicht funktioniert) oder massiv erhöhte Rechnungen bei Cloud-Anbietern wie AWS oder Azure, wenn der Websitebetreiber versucht, durch Skalierung die Anfragen abzufedern. Zwei Wochen später ist eine DDoS-Attacke auf die Deutsche Bahn erfolgt – die öffentliche Wahrnehmung hat natürlich nicht positiv zum Image beigetragen. Als Betreiber hat man allerdings relativ wenig Werkzeuge, einen DDoS-Angriff erfolgreich abzuwehren:
- Abschalten des Ziels für die Dauer des Angriffs: einfachste Möglichkeit, allerdings mit Umsatzeinbußen etc. verbunden. Da DDoS-Angriffe in der Regel wenige Minuten bis Stunden dauern häufig aber verkraftbar.
- Skalierung des Ziels: Alternativ kann das Ziel des Angriffs mit (deutlich) mehr Ressourcen ausgestattet werden, um weiterhin alle Anfragen bedienen zu können. Je nach Größe eines Angriffs möglich, ggf. aber mit sehr hohen Kosten verbunden.
- Filtern der Angriffe: Der schönste und zugleich schwierigste Weg: Die Angreifer durch eine Firewall gezielt zu filtern und ihren Zugang zu unterbinden. Besonderheit eines DDoS-Angriffs ist aber das erste “D”: “distributed”. Der Angriff wird durch viele tausende bis hunderttausende Clients durchgeführt, wodurch jeder einzelne Client nur sehr wenig Zugriffe durchführt und dadurch in einer Firewall überhaupt nicht erkannt wird. Zudem benötigt die Filterung eine zentrale Firewall, die von der Dimensionierung her in der Lage ist, alle eingehenden Anfragen sofort bewerten zu können.
- Vorschalten eines Mitigationsdienstes: Möglich ist außerdem, einen zentralen Mitigationsdienst wie z. B. Cloudflare zu nutzen. Dieser fungiert wie ein Türsteher, zeigt allen Nutzern erst eine Seite mit Captcha (“bitte zeigen Sie, dass Sie ein Mensch sind”) an und lässt sie erst nach erfolgreicher Captcha-Lösung durch. Solche Dienste mit extremen Kapazitäten, um auch Millionen Zugriffe pro Sekunde bewältigen zu können, sind durchaus effektiv, haben als Nebeneffekt in ihrer Funktion als Proxy aber Kenntnis aller Zugriffe im Regelbetrieb und können schöne Besucherprofile erstellen.

Abbildung: DDoS-Angrife pro Jahr (Quelle: Cloudflare)
In unserem Fall entschieden wir uns für Variante “Abschalten” und nahmen die betroffene Website für die Dauer des Angriffs offline. Und so schnell, wie der Angriff gekommen war, war er dann auch wieder vorbei – um 23:04 Uhr, also genau 100 Minuten später kehrten die Zugriffe wieder auf ein Normalniveau zurück.

Abbildung: Zugriffsanzahlen pro Minute, X-Achse: Minuten ab 21:00 Uhr. vor Minute 24 und nach Minute 124 sind die üblichen Zugriffszahlen “zu sehen”
Zurück blieben wir mit einem Rätsel: Wer startet einen DDoS-Angriff Sonntagnachts? Und warum so kurz? Und mit einem anhaltenden zweiten DDoS-Angriff, den wir nur per Zufall entdeckt haben: Gleichzeitig mit dem Angriff über HTTP erfolgte ein zweiter Angriff mit konstant 1 Mio. DNS-Anfragen pro 5 Minuten, der auch über den HTTP-Angriff hinaus anhielt. Da wir keinen externen DNS-Server betreiben, wurden diese Anfragen ohnehin von der Firewall verworfen, sorgten aber für einen konstanten Eingangs-Traffic von 20MB/s(!).
Spannend ist dabei, dass es sich zu 50 Prozent um eine sogenannte “DNS Amplification Attach” handelte. Dabei nutzen Angreifer aus, dass DNS-Anfragen sehr klein sind – Antworten jedoch unter Umständen sehr groß sein können. Um das zu nutzen, machen sie Folgendes: Die (kleine) Anfrage wird nicht direkt an das angegriffene Ziel geschickt, sondern an einen unbeteiligten DNS-Server – allerdings mit dem angegriffenen Server als gefälschter Absenderadresse. Dieser schickt die (große) Antwort damit an die gefälschte Absenderadresse und “kippt” den angegriffenen Server damit mit Daten zu – in etwa vergleichbar mit einem Angreifer, der per Telefon Essen bei 100 Lieferdiensten bestellt – als Lieferadresse aber die des Opfers angibt.
Überraschung: Das war nur der Anfang!
Die Lösung erhielten wir am Folgetag: Am Montag, den 09.02. um 9:21 Uhr, erreichte uns eine zweite, diesmal wesentlich größere Welle. Waren es am Vorabend noch 50.000 Zugriffe pro Minute, begann diese Welle gleich mit 1.2 Millionen Zugriffen pro Minute und steigerte sich auf ein Maximum von 6,3 Millionen Zugriffe pro Minute:
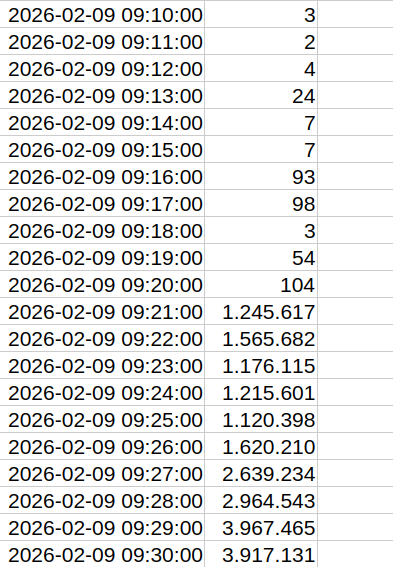
Abbildung: Zugriffszahlen pro Minute im Hauptangriff
Der Angriff am Vorabend war also nur ein Testlauf – entweder, um zu prüfen, wie unsere Infrastruktur reagiert oder um Auftraggebern die Funktionsweise zu demonstrieren.

Abbildung: Zugriffszahlen pro Minute, X-Achse: Minuten ab 08:30 Uhr
Auch in dieser Welle haben wir zunächst die Website offline genommen. Gleichzeitig intern aber den Docker-Stack auf mehrere Nodes verteilt, um nach Abklingen der großen Welle zeitnah wieder online sein zu können.
Anatomie der beiden Angriffswellen
Beide Wellen haben gemeinsam, dass sie sehr unvermittelt starten. Aus Betreibersicht eines Bot-Netzes gar nicht so einfach: Die Clients – häufig als Virus auf einem PC oder als Taschenlampen-oder-sonstwas-App auf einem Handy müssen ja mitbekommen, wann sie welches Ziel angreifen sollen. Das darf aber nicht zu offensichtlich passieren, denn wenn Strafverfolgungsbehörden herausfinden, wo der zentrale Command-and-Control-Server steht, können sie gezielt gegen diesen vorgehen und damit ein komplettes Bot-Netz unschädlich machen, da in Folge keine Befehle mehr erteilt werden können. Häufig werden also mit dem Ziel nicht auffallen zu wollen sehr verwundene Wege genutzt wie z. B. eine codierte Information in bestimmten Tweets oder versteckter Text auf einer Website. Einmal installiert, lässt sich in einem verteilten Virus auch nur schwer ein neues Ziel programmieren. Die Clients dürfen also nicht zu häufig Informationen bei ihrem C&C-Server abrufen, um nicht aufzufallen. Die enge Zeitsteuerung hier ist also “gut gelungen”. 😉
Ebenfalls auffällig ist die Verteilung mit starkem Anfang (in der ersten Welle ab ca. der Hälfte), die vmtl. zum Ziel hat, durch einen starken Anfang sicherzustellen, dass ein Ziel definitiv nicht mehr erreichbar ist und mit sinkender Intensität sicherstellt, dass das Ziel auch offline bleibt.
Aus Botnetz-Betreiber-Sicht auch wichtig: Die/der Besitzer:in eines infizierten Geräts soll natürlich nicht bemerken, dass das eigene Gerät Teil eines Botnetzes ist, denn sonst würde man Gefahr laufen, Bots zu verlieren, falls sich die/der Besitzer:in dann doch mal um einen Virenscanner o. ä. bemüht.
Zahlen, bitte!
Bleibt also die spannende Frage, wie verteilt der Angriff nun tatsächlich war. Dazu haben wir die ~43gb angehäuften Logfiles der betroffenen Domain einmal nach Quell-IP ausgewertet:
- insgesamt haben 182.083 Bots am Angriff teilgenommen (ggf. ein paar weniger, denn es soll in der Zeit ja auch reguläre Zugriffe gegeben haben… 😉 )
- Diese Bots kamen über beide Wellen verteilt auf in Summe 213 Millionen Zugriffe (Anmerkung: Die reale Zugriffszahl wäre deutlich größer gewesen, wenn wir die Seite nicht offline genommen hätten, denn mit allen nachgeladenen Ressourcen wie Bilder, CSS-Dateien, Javascripte, … kommt die Seite auf 60 Anfragen mit in Summe 7,6MB für einen initialen Aufruf ohne Caching)
- ca. die Hälfe der Anfragen wurden dabei durch die Top 100 IP-Adressen verursacht
- Spitzenreiter ist eine IP des US-Rechenzentrumbetreibers Interserver mit ~5 Mio. Zugriffen
- Die Top 25 IP-Adressen stammen aus USA, Indonesien, Brasilien, Sambia, Honkong, China, Seychellen, Singapur, Japan, Deutschland, Türkei, Frankreich, Finnland, Großbritannien und Südafrika
Ausgewertet nach der Anzahl an Zugriffen pro IP-Adresse ergibt sich ein interessantes Muster:

Abbildung: Anzahl IP-Adressen nach Zugriffszahl, X-Achse: Anzahl der Zugriffe je Client, Y-Achse: Anzahl der Clients mit dieser Menge an Zugriffen
Von den in Summe ~180.000 Clients haben ca. 3.000 IPs die Seite nur ein einziges Mal aufgerufen. Dafür haben 12.000 Clients die Seite genau 16x aufgerufen, 24.000 Clients genau 32x, 12.000 Clients genau 48x, 20.000 Clients genau 64x usw.
Warum dieses Muster entsteht, können wir uns nicht so recht erklären – ggf. hat das mit dem schmalen Kommunikationskanal zwischen Command-and-Control-Server und Clients zu tun, sodass dieser bitweise mitteilt, wie häufig zugegriffen werden soll und die Bits stehen für 2er-Potenzen. 
Bleibt zuletzt die Frage nach dem Traffic: Da wir jeweils sehr schnell reagiert haben und die Seite offline genommen haben, ist insgesamt ein Traffic von 117GB entstanden. Davon sind ~50GB allerdings wieder auf den regulären Seitenbetrieb entfallen, den wir ab ca. 13:30 Uhr durch das interne Load Balancing wieder hochfahren konnten trotz ausklingendem Angriff.
Wenn wir die Seite beliebig skaliert und damit alle 213 Millionen Zugriffe bedient hätten, wäre insgesamt ein Traffic von 1,6PB angefallen!
Was lernen wir daraus?
Für uns war dieser Angriff auf jeden Fall der größte DDoS-Angriff bislang. Daraus lassen sich auf jeden Fall ein paar Takes mitnehmen:
- Es ist spannend und gruselig zugleich, bei einem Angriff live zuschauen zu können. Die meisten anderen Angriffe haben eher zu eigen, dass man im Nachgang feststellt, dass schon vor geraumer Zeit Angreifer irgendwo eindringen konnten.
- Der Angriff war sehr stumpf und wenig zielgerichtet. Selbst nachdem wir die Seite offline genommen hatten, lief der Angriff unvermittelt weiter. Mit ein wenig Analyse unserer Infrastruktur hätten sich zudem lohnendere Ziele gefunden als eine Website, die wir HTTP-only aus einem einzigen Docker-Container ausliefern. Auch die Zeit macht bzgl. des Kunden eigentlich keinen Sinn, da zur fraglichen Zeit weder Events liefen, noch Tickets verkauft wurden.
- Mitterweile haben wir mit dem Kunden gemeinsam für diese Domain Cloudflare vorgeschaltet. Das ist zwar ein schöner Schutz vor weiteren Angriffen – gleichzeitig aber auch wenig digital souverän. Am Ende muss dann doch leider wieder ein US-Anbieter herhalten. Es wäre toll, hier auch mehr Europäische Anbieter zu haben, die ähnlich unkompliziert zu nutzen sind!
- pfsense und nginx, die wir jeweils für Firewall und Proxy einsetzen, sind echt krasse Open-Source-Anwendungen! Beide haben jeweils ohne redundante Auslegung zumindest nach Abschalten der Seite (also nur Auslieferung eines Status 403) mühelos selbst die 6 Mio. Anfragen peak pro Minute weggesteckt.
- Parallel zur Verwendung von Cloudflare für den spezifischen Kunden haben wir begonnen, Snort als Intrusion Prevention System (IPS) zu pilotieren – auch wenn, wie oben beschrieben, einzelne kleine Clients in einem DDoS-Angriff schwer zu filtern sind, wäre es zumindest möglich, die Top-Clients zu erwischen und damit die Anfragelast massiv zu reduzieren. Über die Erfahrungen mit Snort werden wir hier im Blog berichten!